K2 Photometry
For my AstroHackWeek project, I decided to hack on the new images coming from NASA's K2 mission, the second generation of the Kepler satellite. The original Kepler mission obtained exquisite precision in the photometry because the satellite's pointing was stable to better than a hundredth of a pixel. For K2, this is no longer the case. Therefore, we'll need to work a little harder to extract useful photometric measurements from these data. That being said, these pointing variations also break some of the degeneracies between the flat field of the detector and the PSF so we might be able to learn some things about Kepler that we couldn't have with the previous data releases.
At the hack week, I got a proof-of-concept implemented but there's definitely a lot to do if we want to develop a general method. The basic idea is to build a flexible probabilistic model inspired by what we know about the physical properties of Kepler and then optimize the parameters of this model to produce a light curve.
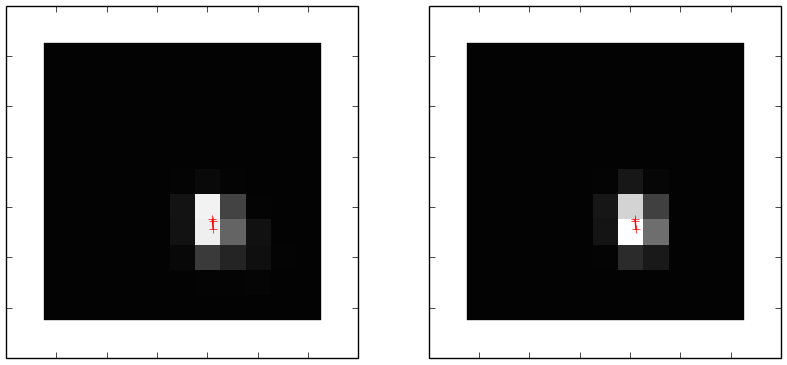
The figure at the top of this page shows a single frame observed in the engineering phase of K2 on the left and, on the right, the optimized model for the same frame. The code lives (and is being actively developed) on GitHub dfm/kpsf and the K2 data can be downloaded from MAST using Python and the git version of kplr.
The Model — The model that I implemented at the hack week has the following parameters:
- the position of the star as a function of time (it currently only fits for a single star… a bad limitation!),
- the brightness of the star as a function of time,
- a spatially constant background level as a function of time,
- a PSF model that is fixed in time (currently a free mixture of three non-concentric Gaussians; with 15 parameters), and
- the response or flat field in each pixel (constant in time).
That is a lot of parameters and, to make matters worse, I found that it was useful to integrate the sub-exposure motion of the star when generating the model for a specific image. This means that I'm actually constraining the position of the star on much shorter time scales than the cadence of Kepler. For the time series associated with the image at the top of this page, we need to fit for about ten thousand parameters. This is a hard problem so I fired up a software package that I'd been wanting to use for a while: Ceres.
The Technology — Ceres Solver is an open source C++ library for solving (big) non-linear least squares problems. This is good because it is designed to work on problems of the scale that we're hitting here but it's bad because I don't have much experience using C++. As far as I can tell, there are two reasons why Ceres can work on our problem:
- it uses "auto diff" to efficiently compute the gradients of the objective function (or residuals between the model and observed images) at compile time, and
- it automatically discovers the sparsity in the problem (many of the parameters only affect the predictions at a single time or in a single pixel) and exploits this structure using sparse linear algebra.
Both of these features would be very hard to implement robustly from scratch but they also tie the code base very tightly to the specific choice of language so I had to struggle through some C++. After some work and after some conversations with Hogg where we discovered some "thinkos" in my original formulation, I got a working prototype and the codebase has fewer than 300 lines of code!
The Results — At this point, the results aren't particularly impressive; the photometry is much more precise than the naive aperture photometry used during the original Kepler mission but it isn't (yet) obviously better than existing data-driven methods. That being said, now that I have a better grasp on how to use this powerful technology, I now have lots of ideas for where to go with this project!
This was only possible because the hack week provided time for me to work on a "hack" that is important but only peripherally related to my PhD thesis project. This, alone, would have made the week worthwhile for me but this was only a small part of what was so great about this workshop. The most benefit came from being in the same room with such an eclectic group of researchers and discussing the many projects that will be hitting these pages over the next weeks and the others that might have been forgotten after too much Scotch.
Comments
Comments powered by Disqus